Part 2 — Set Up GitHub Action Runners on a ComputeBlade Cluster with Shared Cache Storage

Parallelize your CI/CD runs with your ComputeBlade cluster, running GitHub Actions Runner Controller (ARC). In this guide, we will walk through the process of deploying GitHub Action runners on a 4-node ComputeBlade cluster using Kubernetes.
Prerequisites
Before starting, ensure you have:
- A Kubernetes cluster with at least 4 nodes (ComputeBlade setup recommended).
- Longhorn installed as the storage backend
- Administrator access to your Kubernetes cluster.
- An existing GitHub organization (e.g., uptime-lab).
Step 1: Create a Persistent Volume Claim (PVC)
We'll use a PVC to set up a shared storage volume for caching artifacts. This is essential for efficient caching across multiple runners.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: runner-cluster-cache
namespace: <ORG>-github-runners
spec:
accessModes:
- ReadWriteMany
storageClassName: longhorn
resources:
requests:
storage: 50Gi
Replace <ORG> with your organization name, or delete it. Once that's done, save this configuration to a file, e.g., runner-cache-pvc.yaml, and apply it to your cluster:
kubectl apply -f runner-cache-pvc.yaml
Step 2: Deploy GitHub Action Runners
We'll deploy GitHub Action runners using the actions.summerwind.dev/v1alpha1 API. This configuration deploys 4 runners with shared caching and node affinity to ensure proper distribution.
GitHub provides a newer, autoscaling ARC controller, but we want to manually specify how many replicas we are running based on the number of blades we add to our cluster over time. No fancy autoscaling here!
Deployment YAML
apiVersion: actions.summerwind.dev/v1alpha1
kind: RunnerDeployment
metadata:
name: <ORG>-ci-runner
namespace: <ORG>-github-runners
spec:
replicas: 4
template:
metadata:
labels:
app: github-action-runner
region: <OPTIONAL> #ie: us-east-1, my-datacenter-1, etc
city: <OPTIONAL> #ie: new-york, toronto, zurich, etc
cluster-id: cluster-1
spec:
organization: <ORG> # organization OR account... NOT BOTH!
account: <GITHUB USERNAME> # organization OR account... NOT BOTH!
group: <GROUP NAME> # optional, but highly recommended
labels:
- "longhorn-cache-$(REGION)-$(CITY)-$(CLUSTER_ID)"
- "$(CLUSTER_ID)"
- "$(REGION)"
- "$(CITY)"
- "$(BLADE_NAME)"
image: summerwind/actions-runner:latest
env:
- name: RUNNER_WORK_DIRECTORY
value: "/runner/work"
- name: RUNNER_CACHE_DIRECTORY
value: "/runner/cache"
- name: REGION
valueFrom:
fieldRef:
fieldPath: metadata.labels['region']
- name: CITY
valueFrom:
fieldRef:
fieldPath: metadata.labels['city']
- name: CLUSTER_ID
valueFrom:
fieldRef:
fieldPath: metadata.labels['cluster-id']
- name: BLADE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: local-runner-work
mountPath: /runner/work
- name: runner-cache-storage
mountPath: /runner/cache # NOTE: This storage is shared via Longhorn!
volumes:
- name: runner-cache-storage
persistentVolumeClaim:
claimName: runner-cluster-cache
- name: local-runner-work
emptyDir: {}
affinity: # This ensures only one runner agent executes per node
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- github-action-runner
topologyKey: "kubernetes.io/hostname"
Again, replace <ORG> with your organization name on GitHub. If you are just attaching some runners to your GitHub account, delete organization: <ORG> and use account: your-github-username.
Save this configuration to a file, e.g., github-runner-deployment.yaml, and apply it:
kubectl apply -f github-runner-deployment.yaml
Step 3: Verify the Deployment
Check Pods
Verify that the runners are deployed and running. We used uptime as our org value:
kubectl get pods -n uptime-github-runners -o wide
You should see 4 pods with the Running status, one per blade:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
uptime-ci-runner-wz2fk-drcsv 2/2 Running 0 17m 10.1.210.159 blade01 <none> <none>
uptime-ci-runner-wz2fk-f9ng8 2/2 Running 0 17m 10.1.178.219 blade04 <none> <none>
uptime-ci-runner-wz2fk-ghvs4 2/2 Running 0 17m 10.1.134.154 blade02 <none> <none>
uptime-ci-runner-wz2fk-wqdp9 2/2 Running 0 17m 10.1.114.20 blade03 <none> <none>
Inspect Cache Storage
Confirm that the Longhorn PVC is bound and used correctly:
kubectl get pvc -n uptime-github-runners
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
runner-cluster-cache Bound pvc-b7758e45-09af-4be5-94eb-05b0e030df4b 50Gi RWX longhorn <unset> 17m
Check the runner-cluster-cache PVC for its Bound status.
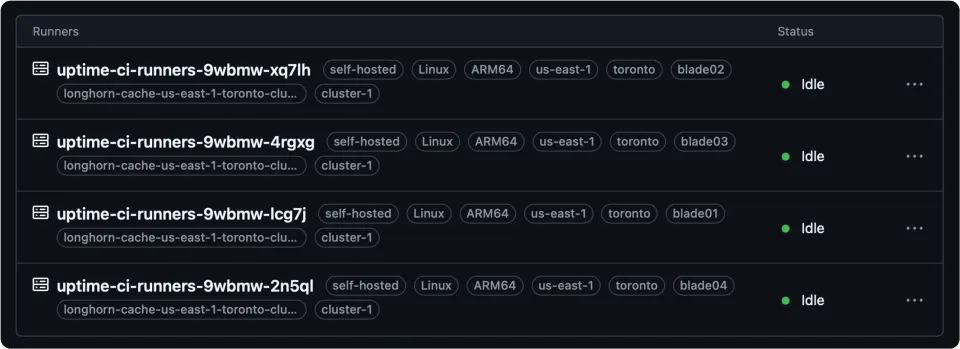
You should also now see the runners in your GitHub organization, if you visit the runners page (Organization Settings > Code, planning, and automation > Actions > Runners):
Step 4: Test the Runners
Assign Runners to a Repository
In your GitHub organization / account, navigate to the Settings > Actions > Runners section. You should see the new runners registered with the labels specified in the deployment (e.g., us-east-1, toronto, longhorn-cache).
Run a Workflow
Create a simple workflow to validate:
name: Test Runners
on:
push:
branches:
- main
jobs:
write-file:
runs-on: [self-hosted, blade01, longhorn-cache]
steps:
- name: Check Out Code
uses: actions/checkout@v3
- name: Write to Cache
run: |
echo "Cached file content" > /runner/cache/test-file.txt
read-file:
needs: write-file
runs-on: [self-hosted, blade02, longhorn-cache]
steps:
- name: Check Out Code
uses: actions/checkout@v3
- name: Read from Cache
run: |
cat /runner/cache/test-file.txt
read-file-2:
needs: write-file
runs-on: [self-hosted, blade03, longhorn-cache]
steps:
- name: Check Out Code
uses: actions/checkout@v3
- name: Read from Cache
run: |
cat /runner/cache/test-file.txt
read-file-3:
needs: write-file
runs-on: [self-hosted, blade04, longhorn-cache]
steps:
- name: Check Out Code
uses: actions/checkout@v3
- name: Read from Cache
run: |
cat /runner/cache/test-file.txt
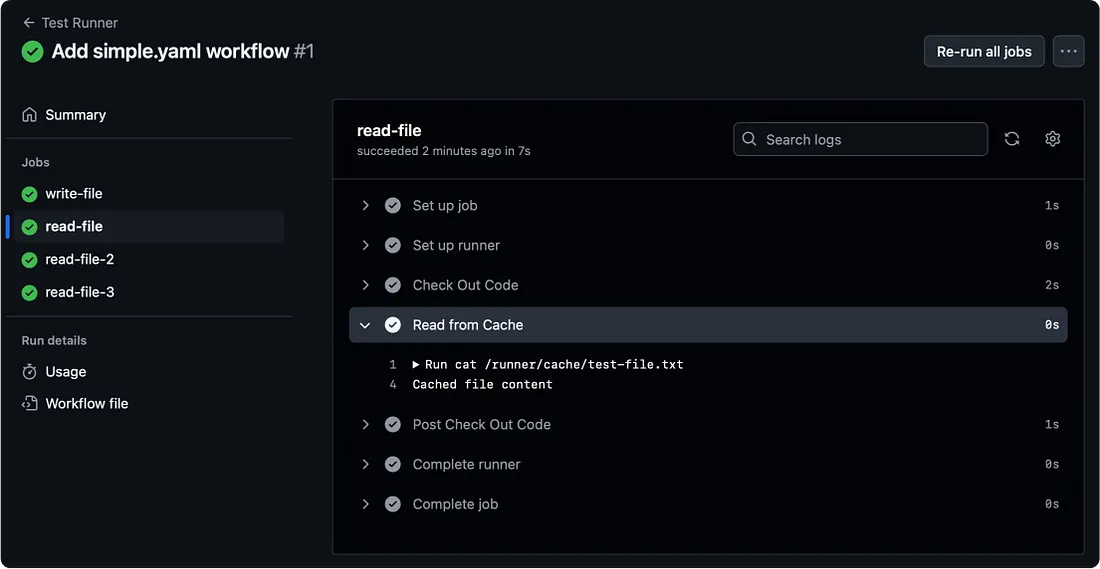
Push the workflow to your repository and verify that it completes successfully. If it does, you should see:

And because we set up a cache manually between all the blades, they are each able to access the file:
Conclusion
If you've reached this point, you will have successfully deployed a scalable setup of GitHub Action runners on a 4-node ComputeBlade cluster with shared Longhorn storage for efficient artifact caching. This configuration ensures high performance and availability for your CI/CD workflows.
To truly unlock the full potential of your CI/CD pipelines, expanding your ComputeBlade cluster is the natural next step. Adding more ComputeBlades not only increases your capacity to handle larger workloads, but also enhances redundancy, scalability, and speed across all your workflows.
Whether you're managing growing teams or scaling up complex deployments, ComputeBlade provides the power and flexibility to meet your evolving demands.
